Reverse Proxy
On my journey to setup the k8s dashboard with proper auth I’ve so far configured an and
. To log in nicely I need a few more things. First I need to have proper URLs with certs so the browser doesn’t complain. To do this I need two things.
- A load balancer to expose IP’s for my services externally
- A reverse proxy to take an incoming address and return the external endpoint for the service to a browser with a cert
MetalLB Load Balancer
The load balancer guide is be using MetalLB so I am going to roll with it.
I followed everything pretty closely except I added a single metallb-service folder with configs and controllers sub folders so things were a bit neater. I also added both kustomizations to one file like with the monitoring stuff.
Everything came up fine:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metallb-controller-77cb7f5d88-snbq5 1/1 Running 0 73s 10.244.2.51 debian03 <none> <none>
metallb-speaker-2zvn4 4/4 Running 0 73s 192.168.0.208 debian03 <none> <none>
metallb-speaker-57nnb 4/4 Running 0 73s 192.168.0.190 kubevip <none> <none>
metallb-speaker-gjv7k 4/4 Running 0 73s 192.168.0.27 debian02 <none> <none>
metallb-speaker-kgs8d 4/4 Running 0 73s 192.168.0.6 debian01 <none> <none>
Even a pod on my control-plane which I don’t usually see.
Next I was instructed to change podinfo from ClusterIP to LoadBalancer so Metallb would assign it an ip.
Well, it did:
kubectl get services -n podinfo
podinfo podinfo LoadBalancer 10.100.130.118 192.168.0.1 9898:30839/TCP,9999:31962/TCP 6d1h
IP Address Mess
This fucked shit up bigtime. 192.168.0.1 is my router and I immediately lost my network connection. Tethering to my phone fix it but I’ll need IPs that are not in use. However, it doesn’t seem like I can use a different subnet than my cluster but I can at least try…
I made a vlan and assigned Metallib - 192.168.4.6-192.168.4.254. I don’t understand how you’d avoid IP conflicts the other way unless I threw the entire cluster on the vLAN which I could do with some extra effort.
thaynes@kubevip:~/workspace/rook-setup$ kubectl get services -n podinfo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
podinfo LoadBalancer 10.100.130.118 192.168.4.6 9898:32176/TCP,9999:30146/TCP 6d1h
Well, it got the ip! And I can hit it from http://kubevip:32176/ but the IP assigned doesn’t seem to do anything, my router doesn’t see it.
Just to see what it looks like on the cluster’s IP I set the range to things not in use, 192.168.0.35-192.168.0.40.
thaynes@kubevip:~/workspace/rook-setup$ kubectl get services -n podinfo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
podinfo LoadBalancer 10.100.130.118 192.168.0.36 9898:32176/TCP,9999:30146/TCP 6d1h
The behavior is exactly the same so maybe all good and I just need ingress next.
VLAN for k8s
I can’t have this load balancer using the pool of IPs the family’s stuff is on so I need to try a VLAN again.
This post is old but looks relevant. I am going to try the config change it references:
FOR TALOS YOU NEED A PATCH SIMILAR TO THIS https://github.com/siderolabs/talos/discussions/7835
KUBE_EDITOR=nano kubectl edit configmap kube-proxy -n kube-system
mode: ipvs
kubectl get po -n kube-system
kubectl delete po -n kube-system <pod-name>
Where pod names to delete are:
kube-proxy-54tg9 1/1 Running 93 (5h58m ago) 94d
kube-proxy-6rpdd 1/1 Running 89 (6h28m ago) 94d
kube-proxy-bhpkd 1/1 Running 92 (6h13m ago) 94d
kube-proxy-xdndt 1/1 Running 25 (5d6h ago) 94d
And new pods are good:
kube-proxy-dmzkc 1/1 Running 0 10s
kube-proxy-kd8l6 1/1 Running 0 4s
kube-proxy-kss5b 1/1 Running 0 17s
kube-proxy-vtkp7 1/1 Running 0 25s
And running the right thing:
kubectl logs kube-proxy-dmzkc -n kube-system | grep "Using ipvs Proxier"
I0811 13:29:10.815775 1 server_linux.go:233] "Using ipvs Proxier"
kubectl logs kube-proxy-kd8l6 -n kube-system | grep "Using ipvs Proxier"
I0811 13:29:17.514617 1 server_linux.go:233] "Using ipvs Proxier"
kubectl logs kube-proxy-kss5b -n kube-system | grep "Using ipvs Proxier"
I0811 13:29:04.407047 1 server_linux.go:233] "Using ipvs Proxier"
kubectl logs kube-proxy-vtkp7 -n kube-system | grep "Using ipvs Proxier"
I0811 13:28:56.515785 1 server_linux.go:233] "Using ipvs Proxier"
I can still hit endpoints which is a good sign.
Now for new IPs! First I am going to try reserving the range with a very simple VLAN:
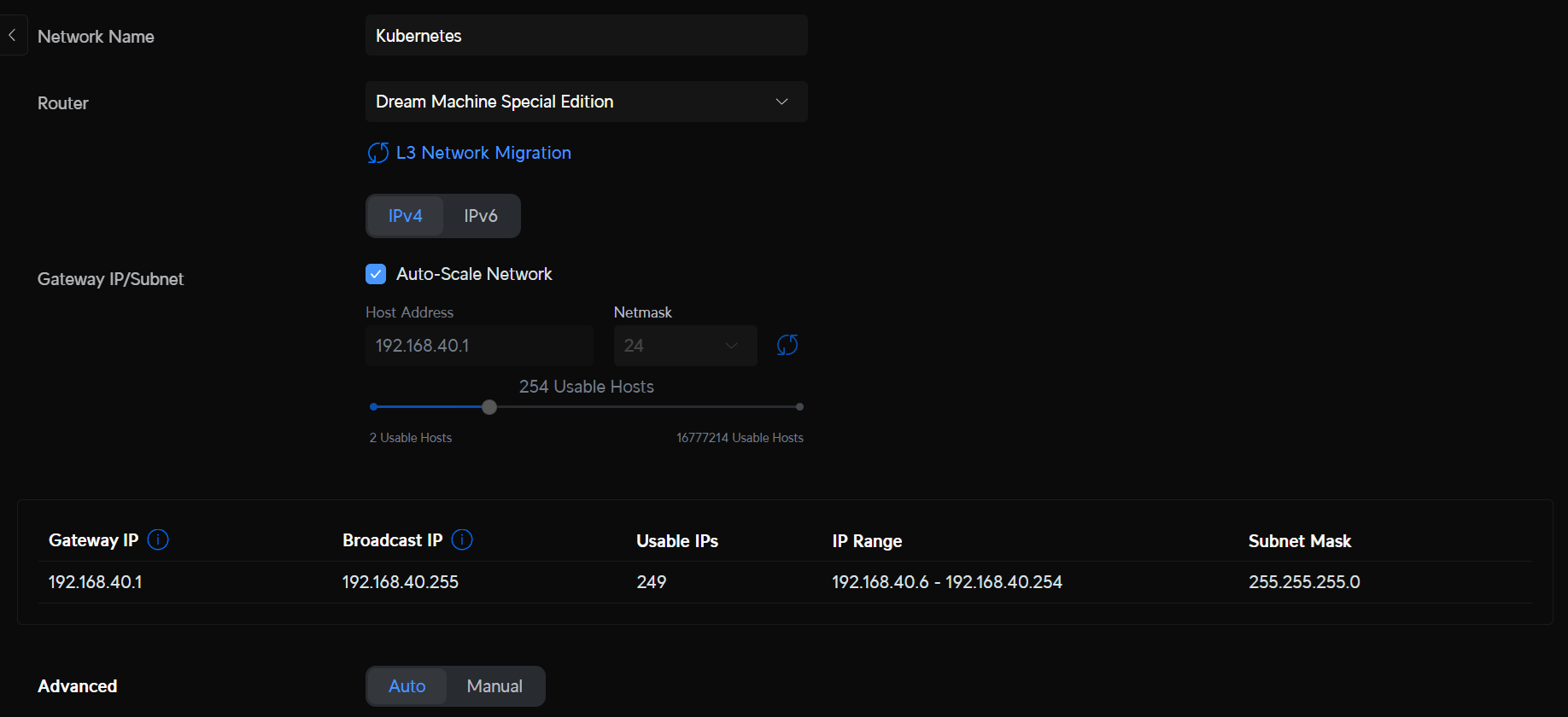
Then I will set my IpAddressPool in metallb to use the range of 192.168.40.60-192.168.40.254. Note I am reserving a bunch in front incase I need to assign NICs this VLAN to get it to work.
Finally, I will change the HelmRelease for traefik to grab one of these IPs:
service:
enabled: true
type: LoadBalancer
annotations:
metallb.universe.tf/loadBalancerIPs: 192.168.40.100
annotations: {}
labels: {}
loadBalancerSourceRanges: []
externalIPs: []
I think that’s all that cares about IPs so time to let it rip!
That Didn’t Work
I can’t hit anything, so I will try to put these VMs on the same VLAN. Gotta remember this command for after the reboot: watch -n1 flux get kustomizations
I am going to temporarily switch vmbr2 over, which is my VPN VLAN, for these three. If I want HA to work I will need to use the same adapter or make a pool I think but this should be find for now.
| host | name | port | old IP range | new IP range |
| pve01 | vmbr2 | enp90s0 | 192.168.3.101/24 | 192.168.40.6/24 |
| pve02 | vmbr2 | enp90s0 | 192.168.3.102/24 | 192.168.40.7/24 |
| pve03 | vmbr2 | enp90s0 | 192.168.3.103/24 | 192.168.40.8/24 |
Now I need to update my DNS entries:
| name | old IP | new IP |
| pve01-25 | 192.168.3.101 | 192.168.40.6 |
| pve02-25 | 192.168.3.102 | 192.168.40.7 |
| pve03-25 | 192.168.3.103 | 192.168.40.8 |
And now I need to update the k8s hosts to use this new network.
| host | old config | new config |
| kubevip | bridge=vmbr0 |
bridge=vmbr2 |
| debian01 | bridge=vmbr0 |
bridge=vmbr2 |
| debian02 | bridge=vmbr0 |
bridge=vmbr2 |
| debian03 | bridge=vmbr0 |
bridge=vmbr2 |
Hopefully the default and k8s subnets can access each other. Time to find out.
Forgot to change the port assignments to the new VLAN in Unifi and everything got the VPN VLAN address.
That helped, now to fix more DNS entries:
| VM | Old IP | New IP |
| kubevip | 192.168.0.190 | 192.168.40.190 |
| debian01 | 192.168.0.6 | 192.168.40.253 |
| debian02 | 192.168.0.27 | 192.168.40.27 |
| debian03 | 192.168.0.208 | 192.168.40.206 |
Now k8s hardcoded IPs broke! First edit sudo nano /etc/kubernetes/kubelet.conf and update server:. Then systemctl restart kubelet.
More IPs in here:
/etc/kubernetes/manifests/kube-apiserver.yaml
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/admin.conf
/etc/kubernetes/controller-manager.conf
/etc/kubernetes/kubelet.conf
/etc/kubernetes/scheduler.conf
/etc/kubernetes/super-admin.conf
/home/thaynes/.kube/config
Regenerate certs with kubeadm init phase certs all and reboot everything for good measure.
That didn’t work…
sudo kubeadm certs check-expiration
sudo kubeadm certs renew all
Didn’t work either. Nuclear option time which is for the best:
thaynes@kubevip:~$ sudo kubeadm init --control-plane-endpoint=kubevip.example --cri-socket /var/run/cri-dockerd.sock --pod-network-cidr=10.244.0.0/16
[sudo] password for thaynes:
W0811 11:25:21.680439 5627 initconfiguration.go:125] Usage of CRI endpoints without URL scheme is deprecated and can cause kubelet errors in the future. Automatically prepending scheme "unix" to the "criSocket" with value "/var/run/cri-dockerd.sock". Please update your configuration!
[init] Using Kubernetes version: v1.30.3
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
That didn’t work - I’m going to go back a level and revamp the whole damn thing.
Ingress
For accessing the cluster from the web we are going to follow this traefik guide. It’s another funky one but we’ve been building up to to this for a while.
Pod was easy to get running following the basic instructions except for the ConfigMap part funky man changed his mind about.
thaynes@kubevip:~/workspace/rook-setup$ kubectl get pods -n traefik
NAME READY STATUS RESTARTS AGE
traefik-79d87d8b84-5fvm6 1/1 Running 0 54s
And we got an IP from the load balancer installed above:
thaynes@kubevip:~/workspace/rook-setup$ kubectl get services -n traefik
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
traefik LoadBalancer 10.109.32.212 192.168.4.8 80:31848/TCP,443:32196/TCP 97s
However http://192.168.4.8:31848/ doesn’t hit the page while http://kubevip:31848/ does. Maybe because I didn’t put the IP on my cluster IP like it says here.
But wait! I can get to the page or get the same result from curl from the VM running the control plane!
curl http://192.168.4.8/
404 page not found
Nightmare Debugging
I guess now I’ll try using it to have local access to podinfo.
thaynes@kubevip:~/workspace/rook-setup$ kubectl get ingress -A
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
podinfo podinfo traefik podinfo.hayneslab 80 44s
Errors in the log:
2024-08-10T00:03:33Z INF Starting provider *acme.ChallengeTLSALPN
2024-08-10T00:08:37Z ERR Error while Peeking first byte error="read tcp 10.244.1.131:8000->10.244.3.0:64522: i/o timeout"
2024-08-10T00:09:48Z ERR Error while Peeking first byte error="read tcp 10.244.1.131:8000->10.244.3.0:24899: i/o timeout"
I see now external DNS is configured for aws. But a better solution may be to use this unifi webhook to keep everything local and be very selective about what goes to cloudflare. However, I’m gonna try cloudflare first…
Few more random things and I get a meaningful error:
2024-08-10T02:10:44Z ERR Skipping service: no endpoints found ingress=podinfo namespace=podinfo providerName=kubernetes serviceName=podinfo servicePort=&ServiceBackendPort{Name:,Number:9898,}
2024-08-10T02:10:45Z ERR Skipping service: no endpoints found ingress=podinfo namespace=podinfo providerName=kubernetes serviceName=podinfo servicePort=&ServiceBackendPort{Name:,Number:9898,}
Check the endpoint:
thaynes@kubevip:~/workspace$ kubectl describe ep podinfo -n podinfo
Name: podinfo
Namespace: podinfo
Labels: app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=podinfo
app.kubernetes.io/version=6.7.0
helm.sh/chart=podinfo-6.7.0
helm.toolkit.fluxcd.io/name=podinfo
helm.toolkit.fluxcd.io/namespace=podinfo
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2024-08-10T02:10:46Z
Subsets:
Addresses: 10.244.1.134
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
grpc 9999 TCP
http 9898 TCP
Events: <none>
Check the service:
thaynes@kubevip:~/workspace$ kubectl describe svc podinfo -n podinfo
Name: podinfo
Namespace: podinfo
Labels: app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=podinfo
app.kubernetes.io/version=6.7.0
helm.sh/chart=podinfo-6.7.0
helm.toolkit.fluxcd.io/name=podinfo
helm.toolkit.fluxcd.io/namespace=podinfo
Annotations: meta.helm.sh/release-name: podinfo
meta.helm.sh/release-namespace: podinfo
metallb.universe.tf/ip-allocated-from-pool: metallb-pool
Selector: app.kubernetes.io/name=podinfo
Type: LoadBalancer
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.130.118
IPs: 10.100.130.118
LoadBalancer Ingress: 192.168.4.7
Port: http 9898/TCP
TargetPort: http/TCP
NodePort: http 32176/TCP
Endpoints: 10.244.1.134:9898
Port: grpc 9999/TCP
TargetPort: grpc/TCP
NodePort: grpc 30146/TCP
Endpoints: 10.244.1.134:9999
Session Affinity: None
External Traffic Policy: Cluster
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal nodeAssigned 19m (x7 over 19h) metallb-speaker announcing from node "debian03" with protocol "layer2"
More fiddling, moved shit to the same subnet to test and I could now hit the IPs. Also the ingress looks like it’s almost there but the host doesn’t have a backend:
thaynes@kubevip:~/workspace$ kubectl describe ingress -n podinfo podinfo
Name: podinfo
Labels: app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=podinfo
app.kubernetes.io/version=6.7.0
helm.sh/chart=podinfo-6.7.0
helm.toolkit.fluxcd.io/name=podinfo
helm.toolkit.fluxcd.io/namespace=podinfo
Namespace: podinfo
Address:
Ingress Class: traefik
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
podinfo.example
/ podinfo:9898 (10.244.1.137:9898)
Annotations: meta.helm.sh/release-name: podinfo
meta.helm.sh/release-namespace: podinfo
Events: <none>
Dashboard also broke..
thaynes@kubevip:~/workspace$ kubectl port-forward $(kubectl get pods --selector "app.kubernetes.io/name=traefik" -n network --output=name) 9000:9000 -n network
kubectl get svc
SIDE BAR This guy figured out how to manage the IPs here
Dashboard works:
http://localhost:9000/dashboard/
The trailing slash was missed.
thaynes@kubevip:~/workspace/open-webui$ kubectl get services -n podinfo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
podinfo LoadBalancer 10.98.51.139 192.168.0.35 9898:30148/TCP,9999:31661/TCP 61m
Maybe this guide will save my ass.
Nope, just more fiddling did.
Getting Somewhere
After a lot of fiddling I was able to get to the podinfo page and traefik dashbaords via my domain entry.
thaynes@kubevip:~/workspace$ kubectl get ingress -A -o wide
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
podinfo podinfo traefik podinfo.example.com 192.168.0.37 80 10h
traefik traefik-dashboard <none> traefik.example.com 192.168.0.37 80 8h
Note traefik still needs: http://traefik.example.com/dashboard/.
This involved:
- Changing a bunch of settings in a way that I didn’t capture exactly what what
- Shutting down NPM on unRAID
- Disabling my port forwarding for 80 and 443 to unRAID
- Adding port forwarding for 80 and 443 to traefik’s IP at 80 and 443
This is great but now all the things I was hosting un unRAID are not exposed and I only have one public IP so I can’t have two entries to my lab. Before I switch back to NPM and set up a local approach, saving public traffic for later, I can try using a cert I made previously in .
SSL Fail
thaynes@kubevip:~/workspace$ kubectl get secrets -A | grep letsencrypt-wildcard-cer
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com kubernetes.io/tls 2 2d11h
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com-staging kubernetes.io/tls 2 2d11h
podinfo letsencrypt-wildcard-cert-example.com kubernetes.io/tls 2 2d10h
podinfo letsencrypt-wildcard-cert-example.com-staging kubernetes.io/tls 2 2d10h
This should be done via:
tls:
- secretName: letsencrypt-wildcard-cert-example.com
hosts:
- podinfo.example.com
Seemingly easy enough…
I now have 443 listed!
thaynes@kubevip:~/workspace$ kubectl get ingress -A
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
podinfo podinfo traefik podinfo.example.com 192.168.0.37 80, 443 11h
traefik traefik-dashboard <none> traefik.example.com 192.168.0.37 80 10h
But I am being redirected to http for some reason: http://podinfo.example.com/.
The cert doesn’t seem to work, I’m going to try and reflect them to the traefik namespace and rename them from:
thaynes@kubevip:~/workspace$ kubectl get certificate -A
NAMESPACE NAME READY SECRET AGE
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com True letsencrypt-wildcard-cert-example.com 2d12h
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com-staging True letsencrypt-wildcard-cert-example.com-staging 2d12h
To:
thaynes@kubevip:~/workspace$ kubectl get certificate -A
NAMESPACE NAME READY SECRET AGE
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com True letsencrypt-wildcard-cert-example.com 8s
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-example.com-staging True letsencrypt-wildcard-cert-example.com-staging 8s
And traefik now has these:
thaynes@kubevip:~/workspace$ kubectl get secret -n traefik
NAME TYPE DATA AGE
letsencrypt-wildcard-cert-example.com kubernetes.io/tls 2 28s
letsencrypt-wildcard-cert-example.com-staging kubernetes.io/tls 2 25s
Go Back A Step
I am going to go over the official traefik guides because the funky shortcuts are not working. First I want to setup whoami. This is used in the getting started example but does not have a helm chart so that’ll be interesting.
First we need to morph the standard secret from the guide into a sealed secret:
apiVersion: v1
kind: Secret
metadata:
name: cloudflare-api-credentials
namespace: traefik
type: Opaque
stringData:
email: [email protected]
apiKey: YOURCLOUDFLAREAPIKEY
I think I can create this from the file traefik-sealed-cf-seed.yaml below:
[default]
email = [email protected]
apiKey = YOURCLOUDFLAREAPIKEY
Then use it to generate sealed secret sealedsecret-cloudflare-api-credentials.yaml with this command:
kubectl create secret generic -n traefik cloudflare-api-credentials \
--from-file=cfcredentials=traefik-sealed-cf-seed.yaml \
-o yaml --dry-run=client \
| kubeseal --controller-name=sealed-secrets --controller-namespace=sealed-secrets --cert pub-cert.pem \
> sealedsecret-cloudflare-api-credentials.yaml
Then creds for the dash:
thaynes@kubevip:~/workspace/traefik$ htpasswd -nb thaynes REDACTED | openssl base64
REDACTED
Now try another sealed secret:
[default]
users = REDACTED
kubectl create secret generic -n traefik traefik-dashboard-auth \
--from-file=traefikdash=traefik-dash-usr.yaml \
-o yaml --dry-run=client \
| kubeseal --controller-name=sealed-secrets --controller-namespace=sealed-secrets --cert pub-cert.pem \
> sealedsecret-traefik-dashboard-auth.yaml
Time to bring in Techno Tim. He says datree is the shit, but they paid him.
Things look better but I can tell my secret is messed up:
2024-08-11T03:08:24Z ERR github.com/traefik/traefik/v3/pkg/server/router/router.go:136 > error="error parsing BasicUser: [default]" entryPointName=websecure routerName=traefik-traefik-dashboard-8869c0e330de477a045a@kubernetescrd
I pulled [default] from the amazon secret but that does not seem to be needed. Fortunately I found what looks like an easy way to convert a vanilla guide secret to a sealed one:
cat traefik-dash-secret.yaml | kubeseal --controller-name=sealed-secrets --controller-namespace=sealed-secrets --cert pub-cert.pem \
--format yaml > sealedsecret-traefik-dashboard-auth.yaml
cat traefik-cf-secret.yaml | kubeseal --controller-name=sealed-secrets --controller-namespace=sealed-secrets --cert pub-cert.pem \
--format yaml > sealedsecret-cloudflare-api-credentials.yaml
WE ARE IN! The secret worked and I could sign in with the user and pw it encrypted.
Making local certs for staging first:
thaynes@kubevip:~/workspace/traefik$ kubectl get challenges -A
NAMESPACE NAME STATE DOMAIN AGE
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-local.example.com-st-169214188 local.example.com 13s
letsencrypt-wildcard-cert letsencrypt-wildcard-cert-local.example.com-st-2968352926 pending local.example.com 13s
Circle Back for Dashboard SSO
Now that more stuff is set up I can circle back and add SSO for the dashboard as we did for the .
I followed the exact same steps as the proxy but I made some tweaks to the outpost config:
log_level: info
docker_labels: null
authentik_host: https://authentik.example.com/
docker_network: null
container_image: null
docker_map_ports: true
refresh_interval: minutes=5
kubernetes_replicas: 3 # Was 1, Boosted to three to match other replicas for authentik
kubernetes_namespace: authentik
authentik_host_browser: ""
object_naming_template: ak-outpost-%(name)s
authentik_host_insecure: false
kubernetes_json_patches: null
kubernetes_service_type: ClusterIP
kubernetes_image_pull_secrets: []
kubernetes_ingress_class_name: traefik # was null but was putting things in the wrong namespace
kubernetes_disabled_components: []
kubernetes_ingress_annotations: {}
kubernetes_ingress_secret_name: authentik-outpost-tls # tried "" but still got errors until I changed kubernetes_ingress_class_name and then I could add this back
I set
Then I swapped the middleware for the traefik dashboard:
@@ -12,7 +12,7 @@ spec:
- match: Host(`traefik.local.example.com`) # TODO setup external-dns to do Unifi entries for local stuff
kind: Rule
middlewares:
- - name: traefik-dashboard-basicauth
+ - name: authentik-auth-proxy
namespace: traefik
services:
- name: api@internal
And it worked like a charm!
Note I am still getting the error for kubernetes_ingress_secret_name not in the traefik namespace, need to get rid of the ingress this automatically created too
2024-08-18 11:42:04 2024-08-18T15:42:04Z ERR github.com/traefik/traefik/v3/pkg/provider/kubernetes/ingress/kubernetes.go:254 > Error configuring TLS error="secret authentik/authentik-outpost-tls does not exist" ingress=ak-outpost-auth-proxy-outpost namespace=authentik providerName=kubernetes
I thought kubernetes_ingress_class_name: to traefik on both outposts fixed the errors. But they seemed to just slow down a bit:
2024-08-18 11:52:16 2024-08-18T15:52:16Z ERR github.com/traefik/traefik/v3/pkg/provider/kubernetes/ingress/kubernetes.go:254 > Error configuring TLS error="secret authentik/authentik-outpost-tls does not exist" ingress=ak-outpost-auth-proxy-outpost namespace=authentik providerName=kubernetes
Will try my trusty kubernetes_ingress_secret_name: certificate-local.example.com secret which is present in the namespace.