Backup Strategy (for everything!)
TODO I should break out the
funky-fluxportion of this an make a parent doc leading into each type of backup.
unRAID Dockers
unRAID is currently backing up on it’s own array using the Appdata.Backup plugin but once the containers are migrated we need a better strategy for at least backing up the Plex db.
Proxmox Backup Server
For this we’ve already followed these steps to run a Proxmox Backup Server VM on unRAID. The only pitfall here was selecting the wrong network adapter and not knowing how to fix it so I just re-did the thing and we’re good.
The cluster is configured for various backups which we should review and update later.
Kubernetes
Kubernetes was set up to create volumesnapshots using rook ceph documentation. At first Gemini looked like a solid option but I don’t see a way to migrate the backups off the ceph cluster with it.
May be able to do something if we look like S3 with S3 seaweedfs or seafile though this might be a bad approach.
Next we need to see if we want Velero or CloudCasa but if we go Velero this guide looks pretty good.
It may also be worth exploring cephgeorep or backy2 for generic ceph backups.
Velero
Before we can follow this guide we need to setup something called flux which will benefit everything we do going further. W
Flux
Install Flux
curl -s https://fluxcd.io/install.sh | sudo bash
Then make a token (REDACTED).
Bootstrap & Run Flux
GITHUB_TOKEN=REDACTED \
flux bootstrap github \
--owner=thaynes43 \
--repository=flux-repo \
--personal \
--path bootstrap
A new namespace was added with the following:
flux-system helm-controller-76dff45854-ghhzd 1/1 Running 0 5m31s
flux-system kustomize-controller-6bc5d5b96-wzjxv 1/1 Running 0 5m31s
flux-system notification-controller-7f5cd7fdb8-z49tr 1/1 Running 0 5m31s
flux-system source-controller-54c89dcbf6-q4wbf 1/1 Running 0 5m31s
The example also added podinfo which tests stuff or something, we’ll find out later.
Now for learning and operating…
To see flux update:
watch -n1 flux get kustomizations
To force an update:
flux reconcile source git flux-system
flux reconcile helmrelease -n <namespace> <name of helmrelease>
See it:
flux get kustomizations
kubectl get helmreleases -n podinfo
Side note, check out some CI stuff here
Now for Velero
Now that the flux stuff is out of the way we can follow this guide in getting Velero up and running. We are also going to need off-cluster support for PVC snapshots which is listed as optional here.
S3 Secret
Right away I got hit with creating some S3 stuff so I figured I’d just go for it. Not really sure what I’m doing but I made a bucket and a key and will see what it does…
Roadblock #1
First I need to learn how to setup sealed secrets
The instructions for installing kubeseal were wrong but this worked:
wget https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.27.1/kubeseal-0.27.1-linux-amd64.tar.gz
tar -xvf kubeseal-0.27.1-linux-amd64.tar.gz
sudo install -m 755 kubeseal /usr/local/bin/kubeseal
Rest of the instructions worked but I didn’t get into Using our own keypair for when the pod with the secrets go down, will need to look that over more when it’s less late.
May also be worth consulting flux docs for sealed-secrets if something goes south.
Back to S3
I can now create and store the sealed secret in a file though I can’t kill the pod or I won’t know how to get it back(?)
kubectl create secret generic -n velero velero-credentials \
--from-file=cloud=velero/awssecret \
-o yaml --dry-run=client \
| kubeseal --controller-name=sealed-secrets --controller-namespace=sealed-secrets > velero/sealedsecret-velero-credentials.yaml
That worked, but now the helm chart values pattern has shifted from the earlier examples…
Adding the values to the helm file worked fine. I only configured S3 and the logs are promising:
thaynes@kubevip:~/workspace/rook-setup/snapshots$ kubectl logs -n velero -l app.kubernetes.io/name=velero
Defaulted container "velero" out of: velero, velero-plugin-for-aws (init)
time="2024-08-04T02:52:22Z" level=info msg="BackupStorageLocations is valid, marking as available" backup-storage-location=velero/default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:126"
time="2024-08-04T02:52:22Z" level=info msg="plugin process exited" backup-storage-location=velero/default cmd=/plugins/velero-plugin-for-aws controller=backup-storage-location id=802 logSource="pkg/plugin/clientmgmt/process/logrus_adapter.go:80" plugin=/plugins/velero-plugin-for-aws
time="2024-08-04T02:53:22Z" level=info msg="plugin process exited" backupLocation=velero/default cmd=/plugins/velero-plugin-for-aws controller=backup-sync id=815 logSource="pkg/plugin/clientmgmt/process/logrus_adapter.go:80" plugin=/plugins/velero-plugin-for-aws
time="2024-08-04T02:53:22Z" level=info msg="Validating BackupStorageLocation" backup-storage-location=velero/default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:141"
time="2024-08-04T02:53:22Z" level=info msg="BackupStorageLocations is valid, marking as available" backup-storage-location=velero/default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:126"
Next I need velero CSI.
wget https://github.com/vmware-tanzu/velero/releases/download/v1.14.0/velero-v1.14.0-linux-amd64.tar.gz
tar -xvf velero-v1.14.0-linux-amd64.tar.gz
sudo install -m 755 velero /usr/local/bin/velero
Now for the backup:
velero backup create hellothere --include-namespaces=default --wait
CLI looks good!
Backup request "hellothere" submitted successfully.
Waiting for backup to complete. You may safely press ctrl-c to stop waiting - your backup will continue in the background.
.
Backup completed with status: Completed. You may check for more information using the commands `velero backup describe hellothere` and `velero backup logs hellothere`.
Debug Automated Backup
Few issues checking if the automated backup worked this AM.
- The backup did not happen
- The logs are in the wrong timezone and gone for when the backup should have happen
- The pod restarted right when the backup would have been triggered given the timezone the pod is logging
However the next backup worked, and I could have tested this via velero backup create --from-schedule=velero-daily-backups, but I still need monitoring…
LATER
velero backup create --from-schedule=velero-daily-backupsworks great
Automated Backup Actually Worked
I noticed two daily backups have been published but the timezone being off is making them in the future:
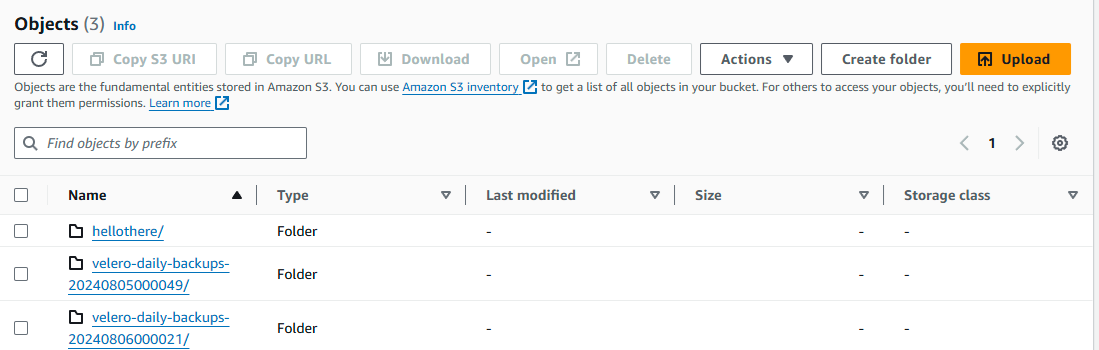
Restore from S3
First we can use velero CLI to see the daily backup schedule is configured:
thaynes@kubevip:~$ velero get schedule
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR PAUSED
velero-daily-backups Enabled 2024-08-03 22:22:19 -0400 EDT 0 0 * * * 240h0m0s 18h ago <none> false
Now we can see what backups we have:
thaynes@kubevip:~$ velero get backups
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
hellothere Completed 0 0 2024-08-03 23:06:57 -0400 EDT 26d default <none>
velero-daily-backups-20240807000057 PartiallyFailed 1 0 2024-08-06 20:00:57 -0400 EDT 9d default <none>
velero-daily-backups-20240806000021 Completed 0 0 2024-08-05 20:00:21 -0400 EDT 8d default <none>
velero-daily-backups-20240805000049 Completed 0 0 2024-08-04 20:00:49 -0400 EDT 7d default <none>
Now we can kill what I backed up:
helm delete open-webui
And try to restore it!
velero create restore --from-backup velero-daily-backups-20240806000021 --wait
So far so good:
Restore completed with status: Completed. You may check for more information using the commands `velero restore describe velero-daily-backups-20240806000021-20240807151327` and `velero restore logs velero-daily-backups-20240806000021-20240807151327`.
Well, it’s back up but the users are gone. Err I don’t think the volume was saved!
Fixing Volumes
First I will try enabling the CSI stuff in the velero helm chart. I ran this command after:
watch -n1 flux get kustomizations
Velero got stuck with Unknown Reconciliation in progress adn then failed a 2m health check.
This was the error:
An error occurred: unable to register plugin (kind=BackupItemActionV2, name=velero.io/csi-pvc-backupper, command=/plugins/velero-plugin-for-csi) because another plugin is already registered for this kind and name (command=/velero)
Fast forward a bunch, from trying things to Flux getting stuck on a HelmRelease that wouldn’t update (deleting it and commiting white space fixed that) I think I am in better shape. The internet says I need deployNodeAgent which gives me these guys:
velero node-agent-5x8t8 1/1 Running 0 3m18s
velero node-agent-fjxvm 1/1 Running 0 3m18s
velero node-agent-hls97 1/1 Running 0 3m18s
So now we can test…
velero backup create testbak1 --include-namespaces=default --wait
Can check it:
velero backup describe testbak1
velero backup logs testbak1
Doesn’t look great here:
Backup Volumes:
Velero-Native Snapshots: <none included>
CSI Snapshots: <none included>
Pod Volume Backups - restic (specify --details for more information):
Completed: 1
But we will try it.
helm delete open-webui
velero create restore --from-backup testbak1 --wait
Restored without error:
Restore completed with status: Completed. You may check for more information using the commands `velero restore describe testbak1-20240807170848` and `velero restore logs testbak1-20240807170848`.
WOOOO my OpenWebUI user is still there! I guess that’s a Pod Volume Backups backup.
Findings Later On
- Velero is snapshotting to the cluster and not moving them
- Need to annotate PVs and PVCs I don’t want to backup like the huge SMB ones
moveSnapshotDatacan be set to migrate the snapshots to S3 (I hope)
Testing it
First, a quick cmd line test:
velero backup create move-data-test --include-namespaces=media-management --snapshot-move-data --wait
S3 Metrics show it’s working and I should stop testing it immediately:
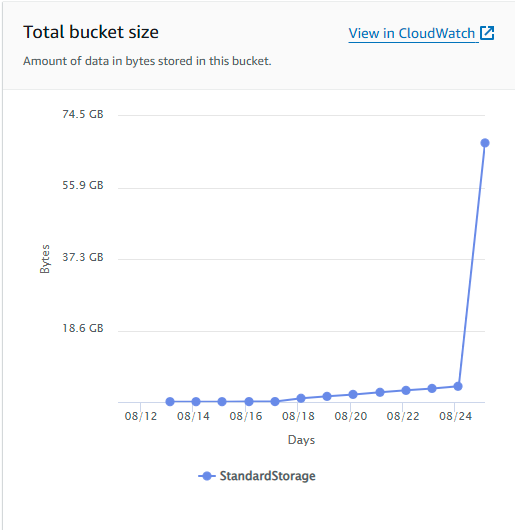
For some reason the metrics lag so this doesn’t even account for what I just did.
Need to annotate the SMB PVs and PVCs that mount the test media and hope that keeps the costs down:
annotations:
velero.io/exclude-from-backup: true
Also deleted the backups with tank present:
thaynes@kubem01:~$ velero delete backup move-data-test -n velero
thaynes@kubem01:~$ velero delete backup move-data-test-smb -n velero
thaynes@kubem01:~$ velero delete backup velero-daily-backups-20240827000047 -n velero
thaynes@kubem01:~$ velero delete backup velero-daily-backups-20240827000047 -n velero
thaynes@kubem01:~$ velero delete backup velero-daily-backups-20240826000046 -n velero
I guess in two days we’ll know if this all works…
That Did Not Work
Pruning Orphans
I deleted backups that inflated what was on S3 but it just orphaned the volumes in restic. First I can use aws cli to see the bucket, config here.
thaynes@kubem01:~$ aws s3 ls
2024-08-03 20:08:56 s3-hayneslab
Connection is good. Now on to the Orphans.
restic -r s3:s3-us-east-2.amazonaws.com/s3-hayneslab/restic/download-clients prune
restic -r s3:s3-us-east-2.amazonaws.com/s3-hayneslab/restic/media-management prune
It wants a password!
kubectl get secret velero-repo-credentials -n velero -o jsonpath="{.data.repository-password}" | base64 --decode
They Aren’t Orphans… Yet
Turns out my smb shares are still being backed up. I need this because I am using restic.
This is a pod level opt-out vs. volume so we are going to need to be SUPER FUCKING CAREFUL.
controllers:
controller-name:
annotations:
backup.velero.io/backup-volumes-excludes: tank
Nuke backups:
velero delete backup velero-daily-backups-20240827114456 -n velero
velero delete backup velero-daily-backups-20240828000048 -n velero
velero delete backup velero-daily-backups-20240828132427 -n velero
velero delete backup velero-daily-backups-20240829000002 -n velero
velero delete backup velero-daily-backups-20240830000003 -n velero
velero delete backup velero-daily-backups-20240831000004 -n velero
thaynes@kubem01:~/workspace/secret-sealing$ velero get backups
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
velero-daily-backups-20240830000003 PartiallyFailed 1 0 2024-08-29 20:00:03 -0400 EDT 8d default <none>
velero-daily-backups-20240829000002 PartiallyFailed 2 3 2024-08-28 20:00:02 -0400 EDT 7d default <none>
velero-daily-backups-20240825000045 PartiallyFailed 2 2 2024-08-24 20:00:45 -0400 EDT 3d default <none>
velero-daily-backups-20240824000055 PartiallyFailed 4 0 2024-08-23 20:00:55 -0400 EDT 2d default <none>
velero-daily-backups-20240823000054 PartiallyFailed 2 0 2024-08-22 20:00:54 -0400 EDT 1d default <none>
velero-daily-backups-20240822000053 PartiallyFailed 2 0 2024-08-21 20:00:53 -0400 EDT 19h default <none>
Maybe we can fix this too?
thaynes@kubem01:~/workspace$ velero backup logs velero-daily-backups-20240831000004 | grep Error
time="2024-08-31T00:00:07Z" level=error msg="Error backing up item" backup=velero/velero-daily-backups-20240831000004 error="daemonset pod not found in running state in node kubem03" error.file="/go/src/github.com/vmware-tanzu/velero/pkg/nodeagent/node_agent.go:112" error.function=github.com/vmware-tanzu/velero/pkg/nodeagent.IsRunningInNode logSource="pkg/backup/backup.go:510" name=metrics-server-557ff575fb-sbr8m
This looks promising.
Tolerations on pod we are erroring:
Tolerations: CriticalAddonsOnly op=Exists
node-role.kubernetes.io/control-plane:NoSchedule op=Exists
node-role.kubernetes.io/master:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Says we can add these to the node agents:
kubectl -n velero edit ds node-agent
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
Or we can annotate the pod to exclude volumes:
backup.velero.io/backup-volumes-excludes=tmp-dir,ube-api-access-xwjr2
To apply:
kubectl -n YOUR_POD_NAMESPACE annotate pod/YOUR_POD_NAME backup.velero.io/backup-volumes-excludes=YOUR_VOLUME_NAME_1,YOUR_VOLUME_NAME_2,...
Or
k -n kube-system annotate pod/metrics-server-557ff575fb-sbr8m backup.velero.io/backup-volumes-excludes=tmp-dir,ube-api-access-xwjr2
pod/metrics-server-557ff575fb-sbr8m annotated
This isn’t ideal because if I recrate things it’ll be gone but let’s see what it does.
Now We Prune?
restic -r s3:s3-us-east-2.amazonaws.com/s3-hayneslab/restic/download-clients prune
restic -r s3:s3-us-east-2.amazonaws.com/s3-hayneslab/restic/media-management prune
VICTORY!
Each command output:
thaynes@kubem01:~/workspace/secret-sealing$ restic -r s3:s3-us-east-2.amazonaws.com/s3-hayneslab/restic/media-management prune
repository 81eaa694 opened (repository version 2) successfully, password is correct
created new cache in /home/thaynes/.cache/restic
loading indexes...
loading all snapshots...
finding data that is still in use for 5 snapshots
[0:00] 100.00% 5 / 5 snapshots
searching used packs...
collecting packs for deletion and repacking
[0:00] 100.00% 3983 / 3983 packs processed
to repack: 466 blobs / 5.025 MiB
this removes: 396 blobs / 4.614 MiB
to delete: 45979 blobs / 66.129 GiB
total prune: 46375 blobs / 66.133 GiB
remaining: 672 blobs / 3.589 MiB
unused size after prune: 0 B (0.00% of remaining size)
repacking packs
[0:00] 100.00% 2 / 2 packs repacked
rebuilding index
[0:00] 100.00% 5 / 5 packs processed
deleting obsolete index files
[0:00] 100.00% 5 / 5 files deleted
removing 3980 old packs
[0:43] 100.00% 3980 / 3980 files deleted
done
And I can see S3 dropped down from 140GB to about 7GB, mostly logs in the monitoring namespace.
Now for the final test:
velero backup create --from-schedule=velero-daily-backups --wait
Some errors but it didn’t upload any media!!!
Fixing the next error
Got these errors:
time="2024-08-31T04:24:48Z" level=error msg="Error backing up item" backup=velero/velero-daily-backups-20240831042446 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=download-clients, name=pvc-smb-tank-k8s-download-clients): rpc error: code = Unknown desc = failed to get VolumeSnapshotClass for StorageClass smb-tank-k8s: error getting VolumeSnapshotClass: failed to get VolumeSnapshotClass for provisioner smb.csi.k8s.io, \n\t\tensure that the desired VolumeSnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="pkg/backup/backup.go:510" name=rdt-client-67d9d9f5dd-4mjkx
time="2024-08-31T04:24:49Z" level=error msg="Error backing up item" backup=velero/velero-daily-backups-20240831042446 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=media-management, name=pvc-smb-tank-k8s-media-management): rpc error: code = Unknown desc = failed to get VolumeSnapshotClass for StorageClass smb-tank-k8s: error getting VolumeSnapshotClass: failed to get VolumeSnapshotClass for provisioner smb.csi.k8s.io, \n\t\tensure that the desired VolumeSnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="pkg/backup/backup.go:510" name=bazarr-7c47cf688d-sgwf9
I may need this to filter these volumes from the snapshot part. But I Think the Restic part is doing what it should now and not copying everything over.
kubectl create cm configmap-velero-volumepolicies \
--from-file config-velero-volumepolicies.yaml -o yaml \
-n velero \
--dry-run=client > configmap-velero-volumepolicies.yaml
Looks like we can simply say “don’t back up volumes that are big” with a config map like this:
config-velero-volumepolicies.yaml
version: v1
volumePolicies:
# See https://velero.io/docs/v1.14/resource-filtering/
- conditions:
# capacity condition matches the volumes whose capacity falls into the range (nothing after comma means that or larger)
capacity: "1Ti,"
action:
type: skip
And running the dry run gives:
apiVersion: v1
data:
config-velero-volumepolicies.yaml: |
version: v1
volumePolicies:
# See https://velero.io/docs/v1.14/resource-filtering/
- conditions:
# capacity condition matches the volumes whose capacity falls into the range (nothing after comma means that or larger)
capacity: "1Ti,"
action:
type: skip
kind: ConfigMap
metadata:
creationTimestamp: null
name: configmap-velero-volumepolicies
namespace: velero
The pvs were set for 100Gi but they just map to whatever is there. I can’t change the pvc after the fact either. If I wanted to I could delete them and go with something more obvious like 10Ti. for tank.k8s and 100Ti for HaynesTower.media.
Test It
Config map is there:
thaynes@kubem01:~/workspace/velero$ k -n velero get configmaps
NAME DATA AGE
configmap-velero-volumepolicies 1 65m
I also renamed the schedule because it wasn’t changing from just adding the config map. New one shows the configmap:
Resource policies:
Type: configmap
Name: configmap-velero-volumepolicies
Now for the test!
velero backup create --from-schedule=velero-hayneslab-backups --wait
Ends up with TONS of errors for pods with no PVCsq
time="2024-08-31T15:36:05Z" level=error msg="Error backing up item" backup=velero/velero-hayneslab-backups-20240831153602 error="volume authentik/dshm has no PVC associated with it" error.file="/go/src/github.com/vmware-tanzu/velero/pkg/util/kube/pvc_pv.go:392" error.function=github.com/vmware-tanzu/velero/pkg/util/kube.GetPVCForPodVolume logSource="pkg/backup/backup.go:510" name=authentik-postgresql-0
Looks like maybe there is a fix. Will try tag: v1.14.1.
WOO finally a clean backup!
velero-hayneslab-backups-20240831155540 Completed 0 0 2024-08-31 11:55:40 -0400 EDT 9d default <none>
Volsync
Running into a lot of things around volsync for hands free recovery. May be worth a look as it only focuses on your volumes.
- https://github.com/backube/volsync